As vision-language models are deployed at scale, understanding their internal mechanisms becomes increasingly critical. Existing interpretability methods predominantly rely on activations, making them dataset-dependent, vulnerable to data bias, and often restricted to coarse head-level explanations. We introduce SITH (Semantic Inspection of Transformer Heads), a fully data-free, training-free framework that directly analyzes CLIP’s vision transformer in weight space. For each attention head, we decompose its value-output matrix into singular vectors and interpret each one via COMP (Coherent Orthogonal Matching Pursuit), a new algorithm that explains them as sparse, semantically coherent combinations of human-interpretable concepts. We show that SITH yields monosemantic, faithful intra-head explanations, validated through reconstruction fidelity and interpretability experiments. This enables precise, interpretable weight-space model edits that amplify or suppress specific concepts, improving downstream performance without retraining. Furthermore, SITH reveals how fine-tuning primarily reweights a stable semantic basis rather than learning entirely new features.
How SITH Works
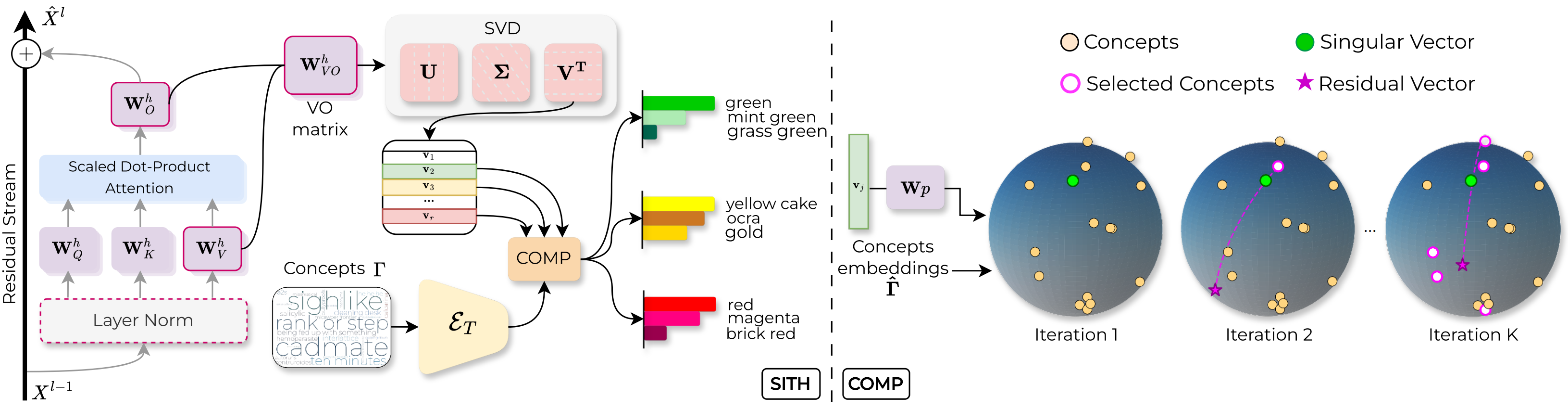
For each attention head, SITH isolates its value-output weight matrix WVO and factorizes it into r singular vectors { vj } via SVD. These vectors capture the head’s dominant computational directions — directly from weights, requiring no images, activations, or labels.
Each singular vector is decomposed by COMP (Coherent Orthogonal Matching Pursuit) into a sparse, non-negative combination of concept embeddings drawn from a textual dictionary Γ (e.g., ConceptNet). Unlike standard matching pursuit, COMP adds a coherence term that favours concepts semantically consistent with those already selected — producing explanations that read as meaningful groups, not unrelated word lists.
What Do Individual Heads Encode?
By considering the first few singular vectors of each Value-Output matrix, which represent the dominant directions of information flow through each head, we can identify the primary functional role of each head. Exploring these singular vectors reveals striking semantic structure: many individual heads naturally specialize in distinct, coherent themes, such as locations, colors, or materials. Furthermore, we observe the same phenomenon across all examined CLIP-trained models, suggesting that this semantic specialization is a universal property of CLIP-trained models. As shown below, the exact same functionally specialized heads emerge across vastly different model capacities and architectures, from ViT-B/32 to MobileCLIP.
Interpretable Model Editing with SITH
Because SITH operates directly on weights, its decompositions are immediately actionable. By scaling the singular values associated with identified concept directions, we can surgically modify CLIP’s behavior — suppressing unwanted features or amplifying task-relevant ones — with no training, no labeled data, and no gradient computation.
On Waterbirds, CLIP can exploit background habitat cues (water vs. land) rather than bird appearance to classify the two classes (waterbird vs. landbird). Thus, we use SITH to identify and suppress the singular vectors encoding background information, without any additional training or labels. This simple edit improves worst-group accuracy by a wide margin (+22.7pp), outperforming TextSpan, a recent method that removes spurious features by ablating entire heads, showing that more fine-grained editing can be more effective.
47.9% → 70.6%
CLIP can encode and retrieve unsafe visual content, thus requiring costly retraining to meet safety standards. Instead, we use SITH to identify the singular vectors associated with nudity and/or violence, and suppress them to create a safer model without any training or labeled data. On the ViSU benchmark, the edited model improves retrieval recall on unsafe visual queries, in particular for unsafe visual queries.
38.9% → 40.4%
For a target classification task, we use SITH to measure the alignment between the semantic content of each singular vector and task-relevant concepts. We then edit the model by rescaling proportionally the singular values, so as to amplify relevant directions and downweight irrelevant ones. This simple edit yields consistent gains across Flowers 102, FGVC-Aircraft, and DTD, without any training, labeled data, or gradient computation.
76.5% → 77.5%
BibTeX
@inproceedings{gentile2026sith,
title = {From Weights to Concepts: Data-Free Interpretability of {CLIP} via Singular Vector Decomposition},
author = {Gentile, Francesco and Dall'Asen, Nicola and Tonini, Francesco and Mancini, Massimiliano and Vaquero, Lorenzo and Ricci, Elisa},
year = 2026,
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}
}